并查集
并查集是我认为最巧妙优雅的一种数据结构,他主要适用于解决元素分组和不相交集合的合并和查询问题。
并查集也非常简单,但是,并查集在比赛中非常常用,能够极大的降低算法复杂度得数据结构,是必须要掌握熟练的。
本节课的难度相对较低,无论是实现方式还是算法原理。
知识点
1.并查集的原理与实现方式 2.并查集的路径压缩 3.启发式合并
并查集
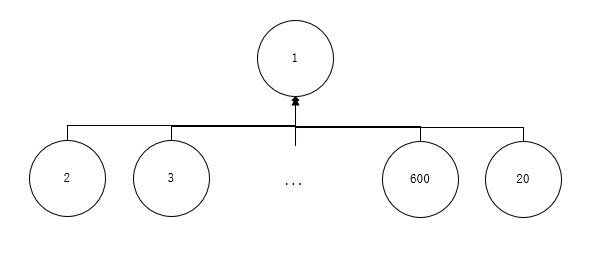
并查集是大量的树(单个节点也算是树)经过合并生成一系列家族森林的过程。
每个集合也就是每棵树都是由根节点确定,也可以理解为每个家族的族长就是根节点。
举个数字和字母的例子如下。
初始森林: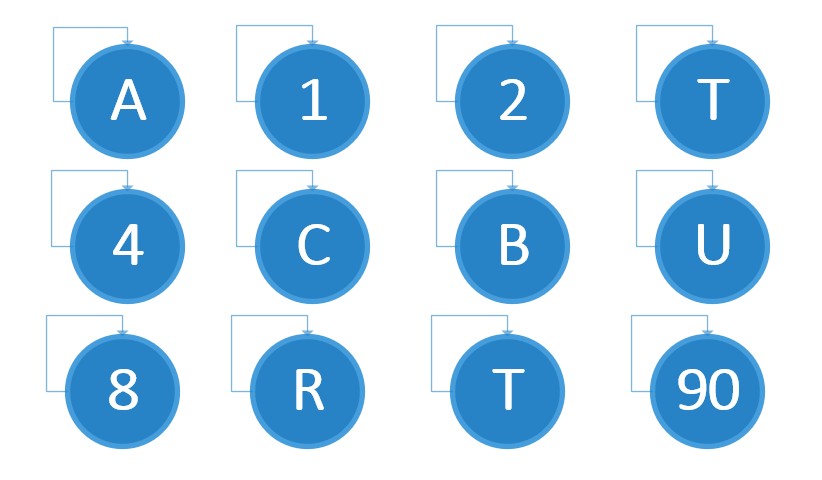
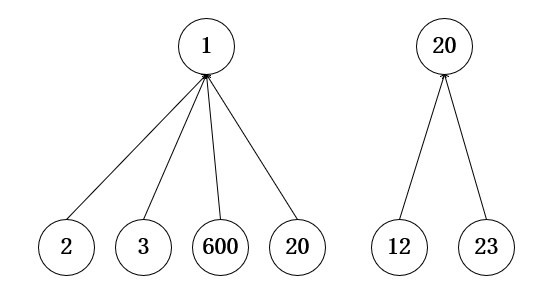
经过的一系列合并后的状态(不唯一,举个栗子):
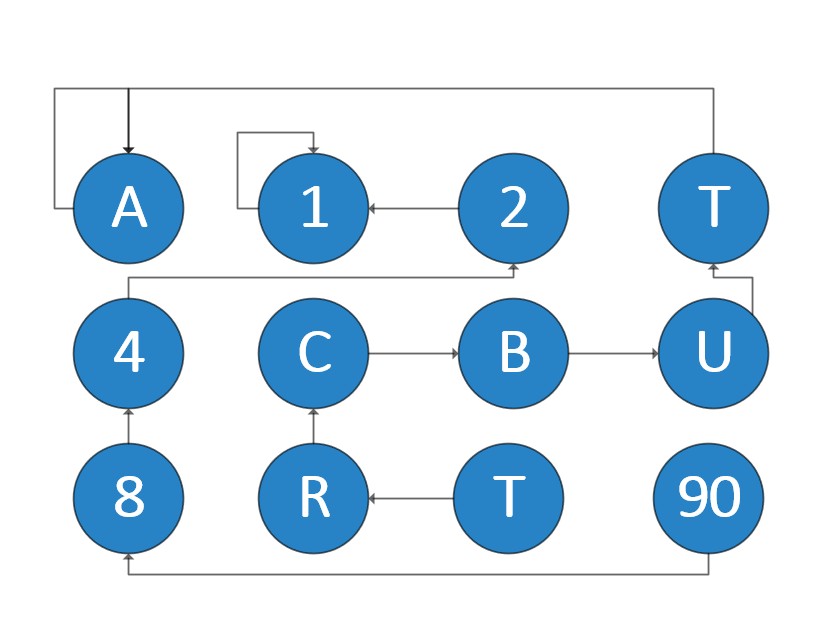
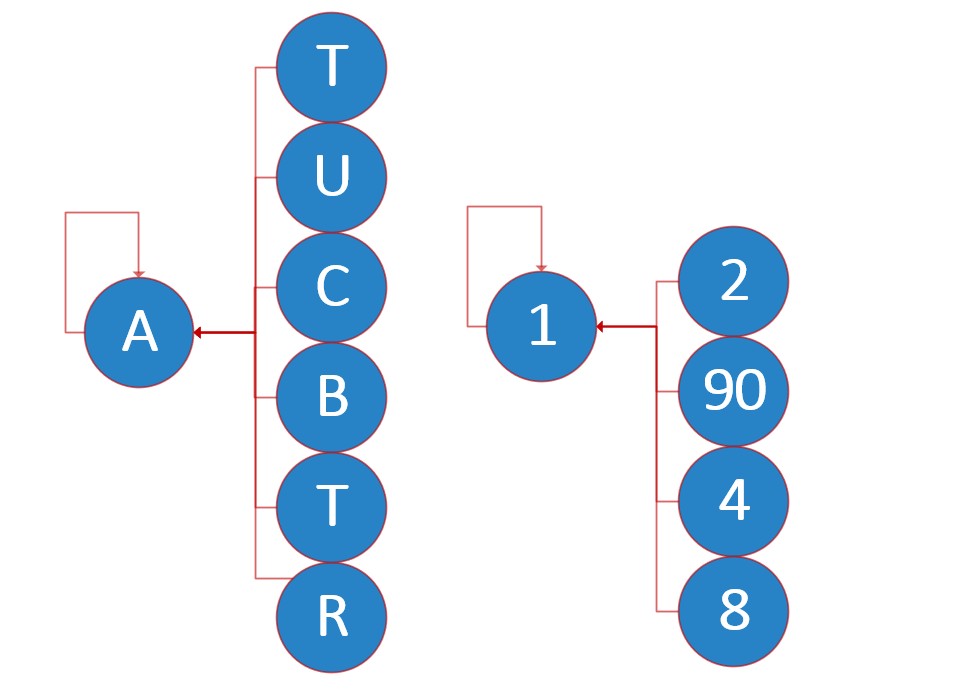
最终合并后的状态:
注:示意图的位置与存储物理位置无关,只代表逻辑关系。
并查集的存储结构
并查集采用数组表示整个森林,初始时每个森林的树根为自己。
C++ 存储与初始化:
1
2
3
4
5
6
7
8
9
10
11
12
|
# define Maxn 200
int fa[Maxn+1]
void init()
{
for(int i =0;i<=Maxn; i++)
fa[i]=i;
}
|
Python 存储与初始化:
1
2
3
4
5
6
7
8
9
10
11
12
|
Maxn = 200
fa = []
def init():
for i in range(Maxn + 1):
fa.append(i)
|
Java 存储与初始化:
1
2
3
4
5
6
7
8
9
10
11
12
|
static final int Maxn = 200;
static int fa[]=new int[Maxn+1];
static void init() {
for(int i=0 ;i<=Maxn;i++)
fa[i]=i;
}
|
查询
一般用递归法实现对代表元素的查询:递归访问父节点,直至根节点(根节点的标志就是父节点是本身)。
根节点相同的两个元素属于同一个集合,上面也说到了。所以判断 A,B 是否属于一个集合直接判断 find(A)和 find(B)是否相同即可。
由于代码比较简单,我们先给出查询的代码:
C++ 查询:
1
2
3
4
5
6
7
8
|
int find(int x)
{
if(fa[x] == x)
return x;
else
return find(fa[x]);
}
|
Python 查询:
1
2
3
4
5
6
7
8
|
def find(x):
if fa[x] == x:
return x
else:
return find(fa[x])
|
Java 查询:
1
2
3
4
5
6
7
8
9
|
static int find(int x)
{
if(fa[x] == x)
return x;
else
return find(fa[x]);
}
|
我们这里有一个问题,当树的链很长时,比如:
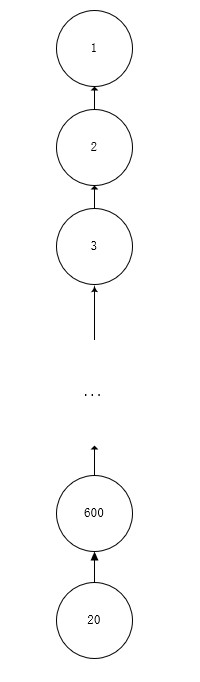
如果每次都查询最后一个,那么他就要经过多次递归,非常消耗时间,这时候我们就要引入路径压缩。
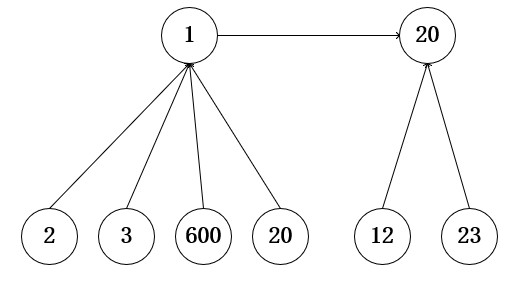
路径压缩
路径压缩是为了解决当树的高度过高的时候,提高查询时效的方法。
解决方式也很简单,在递归的同时将路径压缩,那么上面的图经过一次查询后的效果如下。
其实,实现方式也非常简单,只需要将查询代码修改即可,代码如下:
C++ 查询带路径压缩:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
int find(int x)
{
if(x == fa[x])
return x;
else
{
fa[x] = find(fa[x]);
return fa[x];
}
}
|
Python 查询带路径压缩:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def find(x):
if fa[x] == x:
return x
else:
fa[x] = find(fa[x]);
return fa[x]
|
Java 查询带路径压缩:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
static int find(int x)
{
if(x == fa[x])
return x;
else
{
fa[x] = find(fa[x]);
return fa[x];
}
}
|
合并
合并的方式很简单,就是把一颗树的根节点设置为另一棵树的根节点即可。
还有一种方式是按秩合并,但是我们使用路径压缩时间复杂度就已经很低了,如果在引入 rank 相对会有些复杂。而且对于我们的使用路径压缩一种方式就已经足够。并且路径压缩和按秩合并一起使用时会影响 rank 准确性,所以我们采用普通的合并与优化后的查找即可。
合并后:
C++ 合并:
1
2
3
4
5
|
void merge(int i, int j)
{
fa[find(i)] = find(j);
}
|
Python 合并:
1
2
3
4
5
|
def merge(x,y):
fa[find(x)] = find(y)
|
Java 合并:
1
2
3
4
5
6
|
static void merge(int i, int j)
{
fa[find(i)] = find(j);
}
|
合并优化:
除此之外还有一个优化是启发式合并,其实这个启发式是泛指有很多的合并算法都叫启发式合并,我们这里讲其中一种常用的启发式合并。合并时,选择哪棵树的根节点作为新树的根节点会影响未来操作的复杂度。我们可以按照子树大小去合并,小的合并到大的,以免发生退化。所以启发式合并的原理是在集合合并时将小的集合合并到大的集合里,也可以使 find 操作复杂度降低到 $O(logn)$,在集合合并时还要增加一个更新集合大小的操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| C++
void merge(int x,int y)
{
x=find(x);
y=find(y);
if(x!=y)
{
if(sz[x]<sz[y])
swap(x,y);
sz[x]+=sz[y];
fa[y]=x;
}
}
Java
public void merge(int x, int y) {
x = find(x);
y = find(y);
if (x != y) {
if (sz[x] < sz[y]) {
swap(x, y);
}
sz[x] += sz[y];
fa[y] = x;
}
}
python
def merge(x, y, sz, fa):
x = find(x, fa)
y = find(y, fa)
if x != y:
if sz[x] < sz[y]:
swap(x, y, fa)
sz[x] += sz[y]
fa[y] = x
|
如果是一般的并查集题目用路径压缩就可以了,当然两种优化都用的话复杂度可以降得更低。两种优化都使用的话单次操作的复杂度才是 $O(α)$
并查集相关题目讲解
合根植物
题目链接
难度: 简单
标签: 并查集, 2017, 国赛
题目描述:
1
2
3
4
5
6
|
w 星球的一个种植园,被分成 m×n 个小格子(东西方向 m 行,南北方向 n 列)。每个格子里种了一株合根植物。
这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的植物合成为一体。
如果我们告诉你哪些小格子间出现了连根现象,你能说出这个园中一共有多少株合根植物吗?
|
输入描述:
1
2
3
4
5
6
7
8
9
10
|
第一行,两个整数 m,n,用空格分开,表示格子的行数、列数(1≤m,n≤1000)。
接下来一行,一个整数 k (0≤k≤105 ),表示下面还有 k 行数据。
接下来 k 行,每行两个整数 a,b,表示编号为 a 的小格子和编号为 b 的小格子合根了。
格子的编号一行一行,从上到下,从左到右编号。
比如:5×4 的小格子,编号:
|
| 行列 |
① |
② |
③ |
④ |
| ① |
1 |
2 |
3 |
4 |
| ② |
5 |
6 |
7 |
8 |
| ③ |
9 |
10 |
11 |
12 |
| ④ |
13 |
14 |
15 |
16 |
| ⑤ |
17 |
18 |
19 |
20 |
输出描述:
输入输出样例:
示例:
输入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
5 4
16
2 3
1 5
5 9
4 8
7 8
9 10
10 11
11 12
10 14
12 16
14 18
17 18
15 19
19 20
9 13
13 17
|
输出:
样例图例如下:
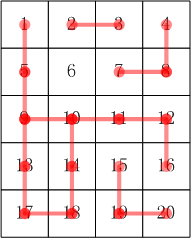
运行限制:
题目解析:
这个题就是一个模板并查集的题目,每次合根就是一次 Merge。
最后答案就是看有多少个根即可,那么就是看有多少个fa[x]=x即可。
直接按照题目编写即可,部分解析直接写进题目。
答案解析:
C++ 描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
#include <bits/stdc++.h>
using namespace std;
# define Maxn 2000000
int fa[Maxn+1];
void init()
{
for(int i =0; i<=Maxn; i++)
fa[i]=i;
}
int find(int x)
{
if(x == fa[x])
return x;
else
{
fa[x] = find(fa[x]);
return fa[x];
}
}
void merge(int i, int j)
{
fa[find(i)] = find(j);
}
int n,m;
int k;
int main()
{
init();
cin>>n>>m>>k;
int a,b;
for(int i=1; i<=k; i++)
{
cin>>a>>b;
merge(a,b);
}
int ans=0;
for(int i=1; i<=n*m; i++)
{
if(fa[i]==i)
{
ans++;
}
}
cout<<ans;
return 0;
}
|
Python 描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
Maxn = 2000000
fa = []
def init():
for i in range(Maxn + 1):
fa.append(i)
def find(x):
if fa[x] == x:
return x
else:
fa[x] = find(fa[x])
return fa[x]
def merge(x,y):
fa[find(x)] = find(y)
if __name__ == '__main__':
n,m=input().split()
k=input()
n=int(n)
m=int(m)
k=int(k)
Maxn=m*n+100
init()
for _ in range(k):
a,b= input().split()
a=int(a)
b=int(b)
merge(a,b)
ans=0
for i in range(m*n):
index=i+1
if(fa[index]==index):
ans+=1
print(ans)
|
Java 描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import java.util.Scanner;
public class Main {
static int Maxn;
static int fa[];
static void init() {
for(int i=0 ;i<=Maxn;i++)
fa[i]=i;
}
static int find(int x)
{
if(x == fa[x])
return x;
else
{
fa[x] = find(fa[x]);
return fa[x];
}
}
static void merge(int i, int j)
{
fa[find(i)] = find(j);
}
static int n,m;
static int k;
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
n=in.nextInt();
m=in.nextInt();
k=in.nextInt();
Maxn=m*n;
fa=new int[Maxn+100];
init();
int a,b;
for(int i=1; i<=k; i++)
{
a=in.nextInt();
b=in.nextInt();
merge(a,b);
}
int ans=0;
for(int i=1; i<=n*m; i++)
{
if(fa[i]==i)
{
ans++;
}
}
System.out.println(ans);
}
}
|
修改数组
题目链接
难度: 中等
标签: 并查集, 2019, 省赛
题目描述: 给定一个长度为 $N$ 的数组 $A = [A_1,A_2,··· ,A_N]$,数组中有可能有重复出现的整数。
现在小明要按以下方法将其修改为没有重复整数的数组。小明会依次修改$A_2,A_3,··· ,A_N$。
当修改 $A_i$ 时,小明会检查 $A_i$ 是否在 $A_1$ ∼ $A_i−1$ 中出现过。如果出现过,则小明会给 $A_i$ 加上 1 ;如果新的 $A_i$ 仍在之前出现过,小明会持续给 $A_i$ 加 1 ,直 到 $A_i$ 没有在 $A_1$ ∼ $A_i−1$ 中出现过。
当 $A_N$ 也经过上述修改之后,显然 $A$ 数组中就没有重复的整数了。
现在给定初始的 $A$ 数组,请你计算出最终的 $A$ 数组。
输入:
第一行包含一个整数 $N$。
第二行包含 $N$ 个整数 $A_1,A_2,··· ,A_N$。
其中,$1 \leq N \leq 10^5,1 \leq A_i \leq 10^6$。
输出:
输出 $N$ 个整数,依次是最终的 $A_1,A_2,··· ,A_N$。
输入输出样例:
输入
输出
运行限制:
题目解析:
第一步,先初始化并查集。
第二步,读入数组并作如下处理:
如果这数字在之前没出现过那么他的值应该就是自己,并将其加入集合,此后再出现这个数字那么就要输出这个数字加 $1$,所以将这个数字的根节点设置为这个数字$+1$ 即可。
如果这个数字之前出现过那么这个数字应该变成根节点的值,根节点的值是之前出现过的值加$+1$。
然后重复简单的逻辑即可,现在是维护一个之前出现过的集合,每个出现过的数字会把根节点设置为比他大 $1$ 的数字,重复这个过程即可完成题意。
我们之前说过,因为输入输出是分开的,这里直接输出就行,不必在使用数组存储。
比如样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
2 1 1 3 4
首先因为 2 没出现过现在,所以初始化后的 fa[2] 等于2
所以直接输出2 即可。
此时 2 已经出现过了,下次遇见2就要输出3,所以这里我们使fa[2]等于3
或者使用merge(2,3);
然后输入1,因为1 也没有出现过,所以重复 2 的操作即可。
输出fa[1]。
令fa[1]=2,但是fa[2]=3,因为2也出现过
这样fa[1]=fa[2]=3
当然这里只需要执行merge(2,3)
然后输入1,因为1 之前出现过,而且他的值我们之前也处理好了,直接输出即可。
输出fa[1],即3。
使用merge(3,4)
然后重复上述过程,代码如下:
输入X :Input(X)
找到根节点: X=find(X);
输出应该是多少:Print(X)
将根节点加+1处理:merge(X,X+1);
|
答案解析:
C++ 描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
#include <bits/stdc++.h>
using namespace std;
# define Maxn 2000000
int fa[Maxn+1];
void init()
{
for(int i =0; i<=Maxn; i++)
fa[i]=i;
}
int find(int x)
{
if(x == fa[x])
return x;
else
{
fa[x] = find(fa[x]);
return fa[x];
}
}
void merge(int i, int j)
{
fa[find(i)] = find(j);
}
int main()
{
init();
int n;
cin>>n;
for(int i=0; i<n; i++)
{
int t;
cin>>t;
t=find(t);
cout<<t<<" ";
merge(t,t+1);
}
return 0;
}
|
Python 描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
Maxn = 2000000
fa = []
def init():
for i in range(Maxn + 1):
fa.append(i)
def find(x):
if fa[x] == x:
return x
else:
fa[x] = find(fa[x]);
return fa[x]
def merge(x,y):
fa[find(x)] = find(y)
if __name__ == '__main__':
n=input()
A=input().split()
A=list(map(int,A))
Maxn=len(A)+100
init()
for i in range(len(A)):
t=find(A[i])
print(t,end=" ")
merge(t,t+1)
|
Java 描述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| import java.util.Scanner;
public class Main {
static int Maxn=1000005;
static int fa[];
static void init() {
for(int i=0 ;i<=Maxn;i++)
fa[i]=i;
}
static int find(int x)
{
if(x == fa[x])
return x;
else
{
fa[x] = find(fa[x]);
return fa[x];
}
}
static void merge(int i, int j)
{
fa[find(i)] = find(j);
}
static int n,m;
static int k;
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
n=in.nextInt();
fa=new int[Maxn+100];
init();
for(int i=1; i<=n; i++)
{
int t;
t=in.nextInt();
t=find(t);
System.out.print(t+" ");
merge(t,t+1);
}
}
}
|
总结
并查集的思想非常简单,但是我们也看到了题目有点复杂,稍微一点改变就是另一种方向。并查集代码实现非常简单,但重点还是看对于题目的把握,这个数据结构不仅直接出题目,并且也会杂糅到别的算法里面,所以他的应用非常广泛,需要我们牢牢地掌握。