数据结构刷题题单
Last Update:
P1996 约瑟夫问题
题目描述
$n$ 个人围成一圈,从第一个人开始报数,数到 $m$ 的人出列,再由下一个人重新从 $1$ 开始报数,数到 $m$ 的人再出圈,依次类推,直到所有的人都出圈,请输出依次出圈人的编号。
注意:本题和《深入浅出-基础篇》上例题的表述稍有不同。书上表述是给出淘汰 $n-1$ 名小朋友,而该题是全部出圈。
输入格式
输入两个整数 $n,m$。
输出格式
输出一行 $n$ 个整数,按顺序输出每个出圈人的编号。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
$1 \le m, n \le 100$
解题思路:
由于这题数据范围非常小,因此可以用很多比较奇怪的算法。不过,命题者的初衷是希望我们使用链表进行模拟。
在这里,我使用了一个结构体 Peo 存储一个双向链表:
1 | |
其中 ID 代表这个人的编号,输出时使用,另外两个指针分别指向上一个和下一个人,不过我们先要对其初始化。 使用两个变量 tot, outNum 来分别存储总人数和出局的数,然后让链表之间互相链接,最后首尾相连。
1 | |
链表初始化完成之后,我们可以使用一个结构体指针 now 来表示我们现在模拟到哪一个人了。
1 | |
最后,我们需要用一种方法来删除链表当中的某一项,可以这样考虑,如果当前需要删除的项是 now, 那么链表中需要修改的变量只有它前一项和后一项的两个指针,在代码实现上,将 now->front 的 next 更改为now->next,然后 now->next 的 front 更改为now->front 就可以了。我们使用一个函数封装这一过程。
1 | |
这样,剩下的就是依据题意模拟了,过程虽然看似有些复杂,但是这大致就是题目期望我们去做的全部过程。
1 | |
方法2:队列
若是使用链表,这题的代码实现复杂程度无疑大大上升了,其实,我们完全用不着那么麻烦,一个个地报数,可以想象成一个队列,一个人报完数后,判断他所报的数是不是出局的数,如果是,直接弹出,但若不是,将其移动至队尾。
我们使用一个队列 q 进行模拟,在读取总人数和出局数字后,把这些人一个个地压入队列尾部。在使用队列之前,需要先加上头文件 <queue>.
1 | |
完成这些之后,开始模拟,整个过程非常直观,在这里就不详细解释了。以下是完整代码。
1 | |
14-3-2020 UPD: 替换了正文部分错误或模棱两可的表述。规范了第一段代码中不合适的实现细节。
作者:Mickey_snow
解题思路(python)
1 | |
解法2:
1 | |
P1047 [NOIP2005 普及组] 校门外的树
题目描述
某校大门外长度为 $l$ 的马路上有一排树,每两棵相邻的树之间的间隔都是 $1$ 米。我们可以把马路看成一个数轴,马路的一端在数轴 $0$ 的位置,另一端在 $l$ 的位置;数轴上的每个整数点,即 $0,1,2,\dots,l$,都种有一棵树。
由于马路上有一些区域要用来建地铁。这些区域用它们在数轴上的起始点和终止点表示。已知任一区域的起始点和终止点的坐标都是整数,区域之间可能有重合的部分。现在要把这些区域中的树(包括区域端点处的两棵树)移走。你的任务是计算将这些树都移走后,马路上还有多少棵树。
输入格式
第一行有两个整数,分别表示马路的长度 $l$ 和区域的数目 $m$。
接下来 $m$ 行,每行两个整数 $u, v$,表示一个区域的起始点和终止点的坐标。
输出格式
输出一行一个整数,表示将这些树都移走后,马路上剩余的树木数量。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
【数据范围】
- 对于 $20%$ 的数据,保证区域之间没有重合的部分。
- 对于 $100%$ 的数据,保证 $1 \leq l \leq 10^4$,$1 \leq m \leq 100$,$0 \leq u \leq v \leq l$。
【题目来源】
NOIP 2005 普及组第二题
解题思路
1 | |
P5732 【深基5.习7】杨辉三角
题目描述
给出 $n(n\le20)$,输出杨辉三角的前 $n$ 行。
如果你不知道什么是杨辉三角,可以观察样例找找规律。
输入格式
输出格式
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
解题思路
杨辉三角形的规律:
- 1、每个数等于它上方两数之和。
- 2、每行数字左右对称,由1开始逐渐变大。
- 3、第n行的数字有n项。
- 4、第n行数字和为2^(n-1)。(2的(n-1)次方)
- 5 (a+b)^n的展开式中的各项系数依次对应杨辉三角的第(n+1)行中的每一项。
- 6、第n行的第m个数和第n-m个数相等,即C(n,m)=C(n,n-m),这是组合数性质
1 | |
P1160 队列安排
题目描述
一个学校里老师要将班上 $N$ 个同学排成一列,同学被编号为 $1\sim N$,他采取如下的方法:
先将 $1$ 号同学安排进队列,这时队列中只有他一个人;
$2\sim N$ 号同学依次入列,编号为 $i$ 的同学入列方式为:老师指定编号为 $i$ 的同学站在编号为 $1\sim(i-1)$ 中某位同学(即之前已经入列的同学)的左边或右边;
从队列中去掉 $M$ 个同学,其他同学位置顺序不变。
在所有同学按照上述方法队列排列完毕后,老师想知道从左到右所有同学的编号。
输入格式
第一行一个整数 $N$,表示了有 $N$ 个同学。
第 $2\sim N$ 行,第 $i$ 行包含两个整数 $k,p$,其中 $k$ 为小于 $i$ 的正整数,$p$ 为 $0$ 或者 $1$。若 $p$ 为 $0$,则表示将 $i$ 号同学插入到 $k$ 号同学的左边,$p$ 为 $1$ 则表示插入到右边。
第 $N+1$ 行为一个整数 $M$,表示去掉的同学数目。
接下来 $M$ 行,每行一个正整数 $x$,表示将 $x$ 号同学从队列中移去,如果 $x$ 号同学已经不在队列中则忽略这一条指令。
输出格式
一行,包含最多 $N$ 个空格隔开的整数,表示了队列从左到右所有同学的编号。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
【样例解释】
将同学 $2$ 插入至同学 $1$ 左边,此时队列为:
2 1
将同学 $3$ 插入至同学 $2$ 右边,此时队列为:
2 3 1
将同学 $4$ 插入至同学 $1$ 左边,此时队列为:
2 3 4 1
将同学 $3$ 从队列中移出,此时队列为:
2 4 1
同学 $3$ 已经不在队列中,忽略最后一条指令
最终队列:
2 4 1
【数据范围】
对于 $20%$ 的数据,$1\leq N\leq 10$。
对于 $40%$ 的数据,$1\leq N\leq 1000$。
对于 $100%$ 的数据,$1<M\leq N\leq 10^5$。
解题思路
1 | |
P4387 【深基15.习9】验证栈序列
题目描述
给出两个序列 pushed 和 poped 两个序列,其取值从 1 到 $n(n\le100000)$。已知入栈序列是 pushed,如果出栈序列有可能是 poped,则输出 Yes,否则输出 No。为了防止骗分,每个测试点有多组数据,不超过 $5$ 组。
输入格式
第一行一个整数 $q$,询问次数。
接下来 $q$ 个询问,对于每个询问:
第一行一个整数 $n$ 表示序列长度;
第二行 $n$ 个整数表示入栈序列;
第三行 $n$ 个整数表示出栈序列;
输出格式
对于每个询问输出答案。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
解题思路
在python中,对于栈使用的是stack。
可以如下两种编写方式,重构后感觉第二种更适合刷题。
1 | |
1 | |
解题思路2
使用C语言
每个数字只能入栈出栈1次,无法将入栈数字全部出栈的输出No
除出栈入栈数组外多一个数组作为缓冲区外部循环做n次每次将第i个数据放在缓冲区最顶的内存里,进入内循环如果缓冲区最顶的数据与第j个出栈的数据一致就将数据出栈,内循环直到缓冲区没有数据退出内循环,外循环结束时缓冲区没有数据代表出栈成功。
1 | |
P1090 [NOIP2004 提高组] 合并果子 / [USACO06NOV] Fence Repair G
题目描述
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过 $n-1$ 次合并之后, 就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为 $1$ ,并且已知果子的种类 数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有 $3$ 种果子,数目依次为 $1$ , $2$ , $9$ 。可以先将 $1$ 、 $2$ 堆合并,新堆数目为 $3$ ,耗费体力为 $3$ 。接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 $12$ ,耗费体力为 $12$ 。所以多多总共耗费体力 $=3+12=15$ 。可以证明 $15$ 为最小的体力耗费值。
输入格式
共两行。
第一行是一个整数 $n(1\leq n\leq 10000)$ ,表示果子的种类数。
第二行包含 $n$ 个整数,用空格分隔,第 $i$ 个整数 $a_i(1\leq a_i\leq 20000)$ 是第 $i$ 种果子的数目。
输出格式
一个整数,也就是最小的体力耗费值。输入数据保证这个值小于 $2^{31}$ 。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
对于 $30%$ 的数据,保证有 $n \le 1000$:
对于 $50%$ 的数据,保证有 $n \le 5000$;
对于全部的数据,保证有 $n \le 10000$。
解题思路
这是一个典型的哈夫曼树,哈夫曼树是二叉树中的一种完全二叉树
1 | |
首先将两个数组的元素初始值设置为int的最大值,使得后续找最小值时方便,再将数组进行从小到大的排序,当然也是便于寻找最小值。
ok,进入核心步骤,也就是找最小值合并。
有n个堆,那么合并成一个堆只需要n-1次操作,因此循环为n-1次
由于a1(利用了sort函数),a2(每次取最小值合并,下一次合并的堆一定比上一次大)均为从小到大排序
1 | |
那么就可以直接在两个数组中按下标顺序找最小值,i和j起一个指针作用,若该元素已经使用了,就指到下一个元素。通过两次取最小值,找到最小堆合并存入第二个数组中,最后利用ans算出结果
P1449 后缀表达式
题目描述
所谓后缀表达式是指这样的一个表达式:式中不再引用括号,运算符号放在两个运算对象之后,所有计算按运算符号出现的顺序,严格地由左而右新进行(不用考虑运算符的优先级)。
本题中运算符仅包含 $\texttt{+-*/}$。保证对于 $\texttt{/}$ 运算除数不为 0。特别地,其中 $\texttt{/}$ 运算的结果需要向 0 取整(即与 C++ / 运算的规则一致)。
如:$\texttt{3*(5-2)+7}$ 对应的后缀表达式为:$\texttt{3.5.2.-*7.+@}$。在该式中,@ 为表达式的结束符号。. 为操作数的结束符号。
输入格式
输入一行一个字符串 $s$,表示后缀表达式。
输出格式
输出一个整数,表示表达式的值。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
样例 #2
样例输入 #2
1 | |
样例输出 #2
1 | |
提示
数据保证,$1 \leq |s| \leq 50$,答案和计算过程中的每一个值的绝对值不超过 $10^9$。
解题思路
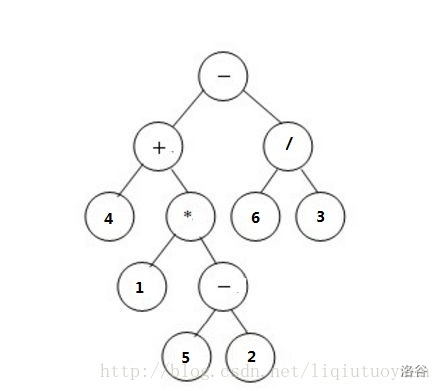
上图是一棵表达式树,对应的后缀表达式是4 1 5 2 - * + 6 3 / -。
可以看出,每个运算符结点都有左子树和右子树,每个数字结点都是叶子节点。
表达式树的中序遍历就是中缀表达式。
运算方式:左子树的结果 运算符 右子树的结果
1 | |
P1241 括号序列
题目描述
定义如下规则:
- 空串是「平衡括号序列」
- 若字符串 $S$ 是「平衡括号序列」,那么 $\texttt{[}S\texttt]$ 和 $\texttt{(}S\texttt)$ 也都是「平衡括号序列」
- 若字符串 $A$ 和 $B$ 都是「平衡括号序列」,那么 $AB$(两字符串拼接起来)也是「平衡括号序列」。
例如,下面的字符串都是平衡括号序列:
(),[],(()),([]),()[],()[()]
而以下几个则不是:
(,[,],)(,()),([()
现在,给定一个仅由 (,),[,]构成的字符串 $s$,请你按照如下的方式给字符串中每个字符配对:
- 从左到右扫描整个字符串。
- 对于当前的字符,如果它是一个右括号,考察它与它左侧离它最近的未匹配的的左括号。如果该括号与之对应(即小括号匹配小括号,中括号匹配中括号),则将二者配对。如果左侧未匹配的左括号不存在或与之不对应,则其配对失败。
配对结束后,对于 $s$ 中全部未配对的括号,请你在其旁边添加一个字符,使得该括号和新加的括号匹配。
输入格式
输入只有一行一个字符串,表示 $s$。
输出格式
输出一行一个字符串表示你的答案。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
样例 #2
样例输入 #2
1 | |
样例输出 #2
1 | |
提示
数据规模与约定
对于全部的测试点,保证 $s$ 的长度不超过 $100$,且只含 (,),[,] 四种字符。
解题思路
参考思路
原题目:扫描一遍原序列,对每一个右括号,找到在它左边最靠近它的左括号匹配,如果没有就放弃。翻译:扫描一遍原序列,当找到一个右括号(即找到一个 ‘ ) ‘ 或者 ‘ ] ‘ 时),以它为起点向左找,找到一个没被标记成功匹配的左括号(即找到一个 ‘ ( ‘ 或者 ‘ [ ‘ ),如果两者匹配的话,标记它们成功匹配,如果不匹配,或者找不到左括号的话,不做任何标记。
原题目:在以这种方式把原序列匹配完成后,把剩下的未匹配的括号补全。
翻译:上面扫描一遍标记完成功匹配的括号之后,扫描一遍序列,对于标记过的括号,则直接输出;对于没有标记的括号,则补全成对输出
举例:如果有个 ‘ [ ‘ 或 ‘ ] ‘ 没被标记匹配,则输出 [ ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42#include <bits/stdc++.h>
using namespace std;
int a[105]; // 标记
int main()
{
int i,j;
string s;
cin >> s;
for (i=0; i<s.length(); i++) {
if (s[i] == ')') { // 找到了右括号
for (j=i-1; j>=0; j--) {
if (s[j] == '(' and a[j] == 0) { // 找到了没被匹配过的左括号且匹配成功
a[i] = a[j] = 1;
break;
}
else if (s[j] == '[' and a[j] == 0) break; // 找到了左括号但匹配失败
}
// 找不到左括号,不做任何操作
}
// 下面同理
else if (s[i] == ']') {
for (j=i-1; j>=0; j--) {
if (s[j] == '[' and a[j] == 0) {
a[i] = a[j] = 1;
break;
}
else if (s[j] == '(' and a[j] == 0) break;
}
}
}
for (i=0; i<s.length(); i++) {
if (a[i] == 0) { // 没有匹配则成对输出
if (s[i] == '(' or s[i] == ')') cout << "()";
else cout << "[]";
}
else cout << s[i]; // 匹配成功则直接输出
}
return 0;
}
P1044 [NOIP2003 普及组] 栈
题目背景
栈是计算机中经典的数据结构,简单的说,栈就是限制在一端进行插入删除操作的线性表。
栈有两种最重要的操作,即 pop(从栈顶弹出一个元素)和 push(将一个元素进栈)。
栈的重要性不言自明,任何一门数据结构的课程都会介绍栈。宁宁同学在复习栈的基本概念时,想到了一个书上没有讲过的问题,而他自己无法给出答案,所以需要你的帮忙。
题目描述
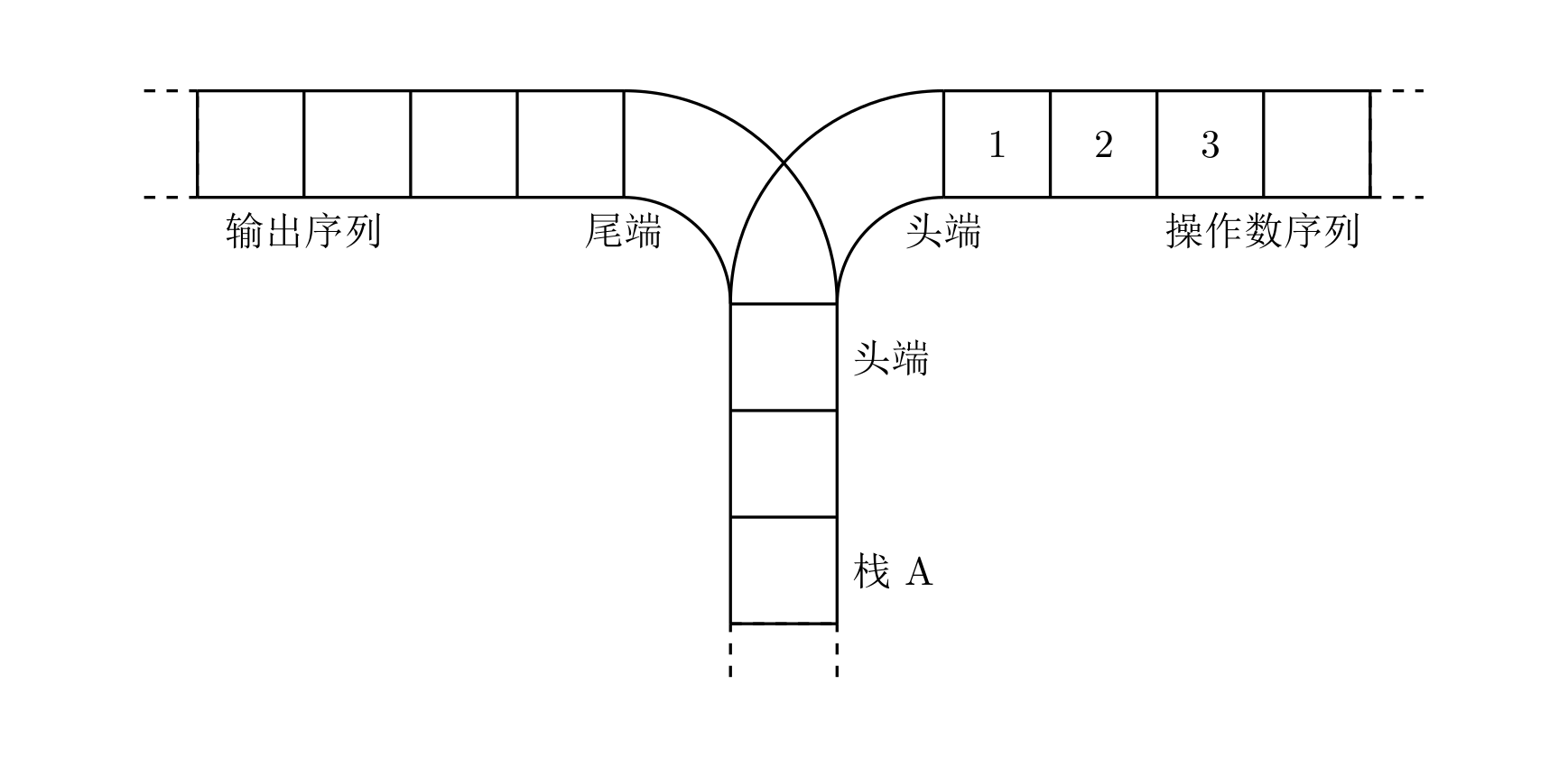
宁宁考虑的是这样一个问题:一个操作数序列,$1,2,\ldots ,n$(图示为 1 到 3 的情况),栈 A 的深度大于 $n$。
现在可以进行两种操作,
- 将一个数,从操作数序列的头端移到栈的头端(对应数据结构栈的 push 操作)
- 将一个数,从栈的头端移到输出序列的尾端(对应数据结构栈的 pop 操作)
使用这两种操作,由一个操作数序列就可以得到一系列的输出序列,下图所示为由 1 2 3 生成序列 2 3 1 的过程。
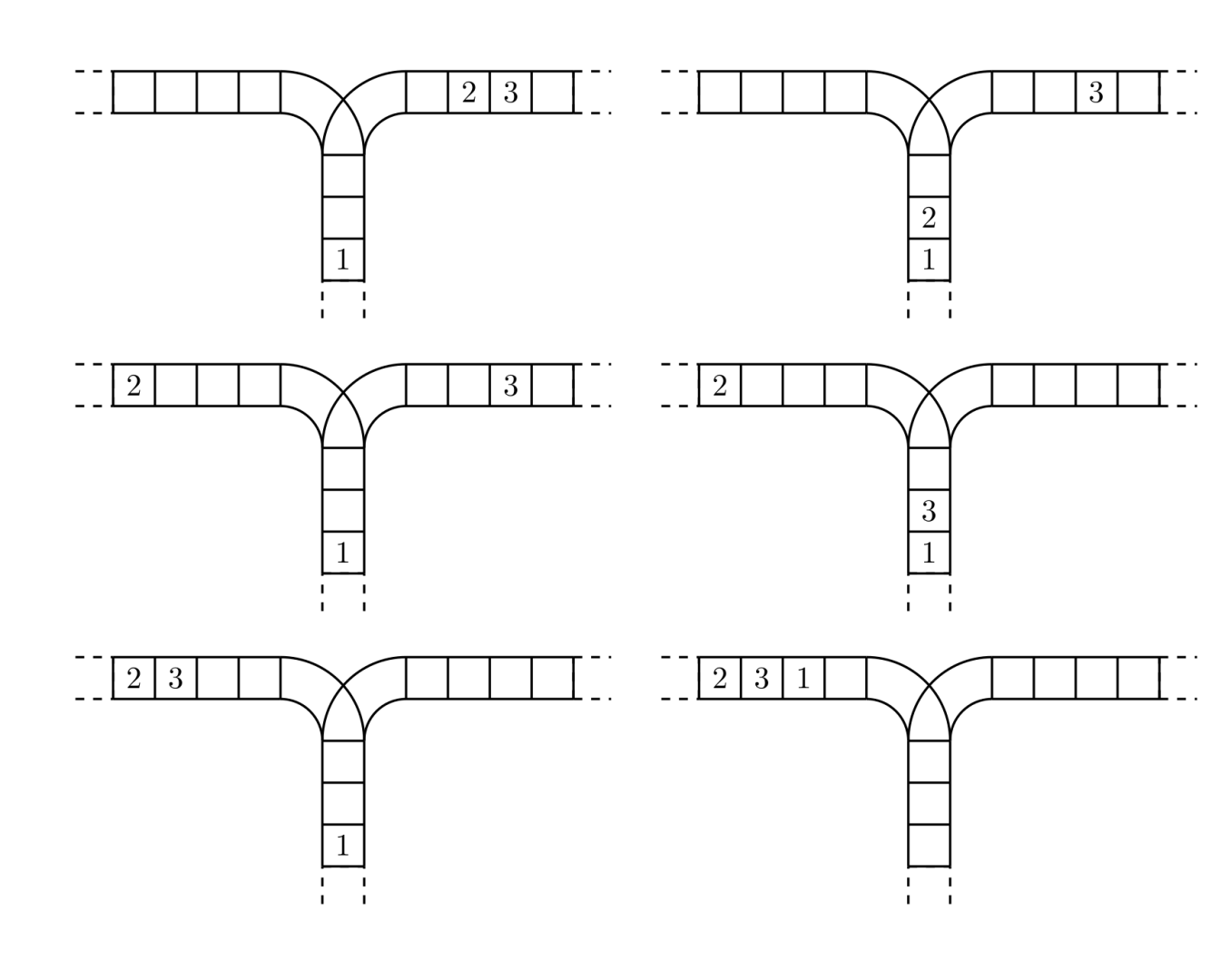
(原始状态如上图所示)
你的程序将对给定的 $n$,计算并输出由操作数序列 $1,2,\ldots,n$ 经过操作可能得到的输出序列的总数。
输入格式
输入文件只含一个整数 $n$($1 \leq n \leq 18$)。
输出格式
输出文件只有一行,即可能输出序列的总数目。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
【题目来源】
NOIP 2003 普及组第三题
解题思路
思路:先定义数组和变量,然后令f[0]=1,f[1]=1,默认f[0]=1纯粹是为了满足表达式计算,无实际意义;然后用卡特兰数递推式方可求出从2开始到n的各个f值,最后输出f[n]即可.
**卡特兰数原理:令h(0)=1,h(1)=1,catalan数满足递推式:h(n)= h(0)h(n-1)+h(1)h(n-2) + … + h(n-1)h(0) (n>=2)
1 | |
P6033 [NOIP2004 提高组] 合并果子 加强版
题目背景
本题除【数据范围与约定】外与 P1090 完 全 一 致。
题目描述
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过 $(n - 1)$ 次合并之后, 就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为 $1$,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有 $3$ 堆果子,数目依次为 $1,2,9$。可以先将 $1$、$2$ 堆合并,新堆数目为 $3$,耗费体力为 $3$。接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 $12$,耗费体力为 $12$。所以多多总共耗费体力为 $3+12=15$。可以证明 $15$ 为最小的体力耗费值。
输入格式
输入的第一行是一个整数 $n$,代表果子的堆数。
输入的第二行有 $n$ 个用空格隔开的整数,第 $i$ 个整数代表第 $i$ 堆果子的个数 $a_i$。
输出格式
输出一行一个整数,表示最小耗费的体力值。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
【数据规模与约定】
本题采用多测试点捆绑测试,共有四个子任务。
- Subtask 1(10 points):$1 \leq n \leq 8$。
- Subtask 2(20 points):$1 \leq n \leq 10^3$。
- Subtask 3(30 points):$1 \leq n \leq 10^5$。
- Subtask 4(40 points):$1 \leq n \leq 10^7$。
对于全部的测试点,保证 $1 \leq a_i \leq 10^5$。
【提示】
- 请注意常数因子对程序效率造成的影响。
- 请使用类型合适的变量来存储本题的结果。
- 本题输入规模较大,请注意数据读入对程序效率造成的影响。
解题思路
参考文章:【洛谷】P6033 合并果子 加强版(配数学证明)_洛谷6033测试数据-CSDN博客
1 | |
P3370 【模板】字符串哈希
题目描述
如题,给定 $N$ 个字符串(第 $i$ 个字符串长度为 $M_i$,字符串内包含数字、大小写字母,大小写敏感),请求出 $N$ 个字符串中共有多少个不同的字符串。
友情提醒:如果真的想好好练习哈希的话,请自觉。
输入格式
第一行包含一个整数 $N$,为字符串的个数。
接下来 $N$ 行每行包含一个字符串,为所提供的字符串。
输出格式
输出包含一行,包含一个整数,为不同的字符串个数。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
对于 $30%$ 的数据:$N\leq 10$,$M_i≈6$,$Mmax\leq 15$。
对于 $70%$ 的数据:$N\leq 1000$,$M_i≈100$,$Mmax\leq 150$。
对于 $100%$ 的数据:$N\leq 10000$,$M_i≈1000$,$Mmax\leq 1500$。
样例说明:
样例中第一个字符串(abc)和第三个字符串(abc)是一样的,所以所提供字符串的集合为{aaaa,abc,abcc,12345},故共计4个不同的字符串。
Tip:
感兴趣的话,你们可以先看一看以下三题:
BZOJ3097:http://www.lydsy.com/JudgeOnline/problem.php?id=3097
BZOJ3098:http://www.lydsy.com/JudgeOnline/problem.php?id=3098
BZOJ3099:http://www.lydsy.com/JudgeOnline/problem.php?id=3099
如果你仔细研究过了(或者至少仔细看过AC人数的话),我想你一定会明白字符串哈希的正确姿势的^_^
提示
对于 $30%$ 的数据:$N\leq 10$,$M_i≈6$,$Mmax\leq 15$。
对于 $70%$ 的数据:$N\leq 1000$,$M_i≈100$,$Mmax\leq 150$。
对于 $100%$ 的数据:$N\leq 10000$,$M_i≈1000$,$Mmax\leq 1500$。
样例说明:
样例中第一个字符串(abc)和第三个字符串(abc)是一样的,所以所提供字符串的集合为{aaaa,abc,abcc,12345},故共计4个不同的字符串。
Tip:
感兴趣的话,你们可以先看一看以下三题:
BZOJ3097:http://www.lydsy.com/JudgeOnline/problem.php?id=3097
BZOJ3098:http://www.lydsy.com/JudgeOnline/problem.php?id=3098
BZOJ3099:http://www.lydsy.com/JudgeOnline/problem.php?id=3099
如果你仔细研究过了(或者至少仔细看过AC人数的话),我想你一定会明白字符串哈希的正确姿势的^_^
解题代码
1 | |
1 | |
解题思路
《洛谷深入浅出基础篇》 p3370字符串哈希——hash表_洛谷p3370-CSDN博客
1 | |
P5250 【深基17.例5】木材仓库
题目描述
博艾市有一个木材仓库,里面可以存储各种长度的木材,但是保证没有两个木材的长度是相同的。作为仓库负责人,你有时候会进货,有时候会出货,因此需要维护这个库存。有不超过 100000 条的操作:
- 进货,格式
1 Length:在仓库中放入一根长度为 Length(不超过 $10^9$) 的木材。如果已经有相同长度的木材那么输出Already Exist。 - 出货,格式
2 Length:从仓库中取出长度为 Length 的木材。如果没有刚好长度的木材,取出仓库中存在的和要求长度最接近的木材。如果有多根木材符合要求,取出比较短的一根。输出取出的木材长度。如果仓库是空的,输出Empty。
输入格式
输出格式
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
解题答案
python版
1 | |
c语言版
1 | |
P5266 【深基17.例6】学籍管理
题目描述
您要设计一个学籍管理系统,最开始学籍数据是空的,然后该系统能够支持下面的操作(不超过 $10^5$ 条):
- 插入与修改,格式
1 NAME SCORE:在系统中插入姓名为 NAME(由字母和数字组成不超过 20 个字符的字符串,区分大小写) ,分数为 $\texttt{SCORE}$($0<\texttt{SCORE}<2^{31}$) 的学生。如果已经有同名的学生则更新这名学生的成绩为 SCORE。如果成功插入或者修改则输出OK。 - 查询,格式
2 NAME:在系统中查询姓名为 NAME 的学生的成绩。如果没能找到这名学生则输出Not found,否则输出该生成绩。 - 删除,格式
3 NAME:在系统中删除姓名为 NAME 的学生信息。如果没能找到这名学生则输出Not found,否则输出Deleted successfully。 - 汇总,格式
4:输出系统中学生数量。
输入格式
输出格式
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
解题思路
题目要求对字符串进行存储、修改、查询、删除、统计数目等操作,考虑到直接对字符串进行上述操作在代码实现和时间复杂度上都不够优,从而想到利用哈希建立映射关系,对哈希函数的返回值进行操作。
代码:
1 | |
当然也可以用 $STL$ 中的 $map$ 来建立映射关系,但在时间常数上要比手打哈希略大。
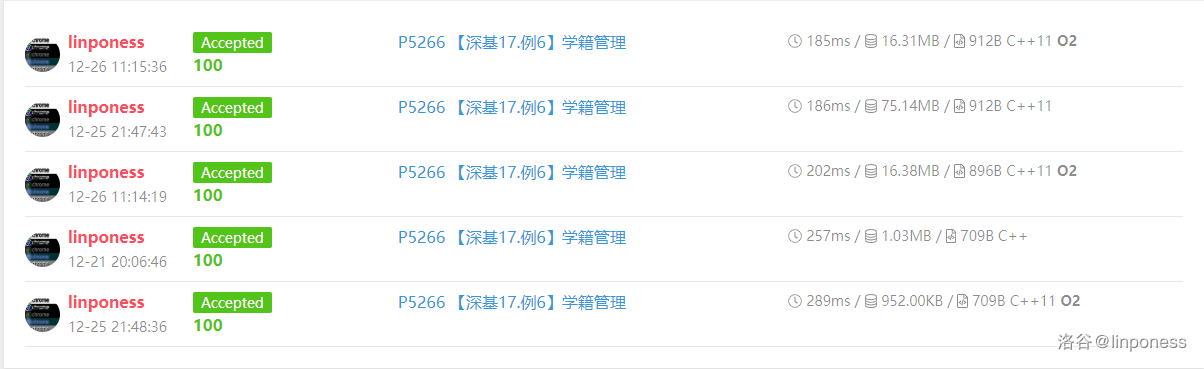
上面三次提交使用的是手打哈希,下面两次提交使用的是 $map$ ,可以明显看出 $map$ 比手打哈希要慢。
代码:
1 | |
作者:linponess 创建时间:2019-12-26 11:45:56
P1102 A-B 数对
题目背景
出题是一件痛苦的事情!
相同的题目看多了也会有审美疲劳,于是我舍弃了大家所熟悉的 A+B Problem,改用 A-B 了哈哈!
题目描述
给出一串正整数数列以及一个正整数 $C$,要求计算出所有满足 $A - B = C$ 的数对的个数(不同位置的数字一样的数对算不同的数对)。
输入格式
输入共两行。
第一行,两个正整数 $N,C$。
第二行,$N$ 个正整数,作为要求处理的那串数。
输出格式
一行,表示该串正整数中包含的满足 $A - B = C$ 的数对的个数。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
对于 $75%$ 的数据,$1 \leq N \leq 2000$。
对于 $100%$ 的数据,$1 \leq N \leq 2 \times 10^5$,$0 \leq a_i <2^{30}$,$1 \leq C < 2^{30}$。
2017/4/29 新添数据两组
解题思路
map 映照容器可以解决这一题
首先,我们来了解一下 map 是个什么东西:
- map 映照容器在头文件中定义,它的元素数据是由一个键值和一个映照数据组成的,键值和映照数据具有一一对应的关系,键值可以是数,也可以是字符。 例如:
键值 映照数据
(name) (score)
Alice 98
Mary 96
156 66
在没有指定比较函数时,元素是从小到大插入的。比较函数只对键值进行比较,元素的各项数据可以通过键值检索出来。
对于这一道题,我们可以把 A-B=C 改成 B+C=A,再通过 map 进行映照,就可以得出答案。
code:
1 | |
作者:onepeople666 创建时间:2020-02-04 13:12:37
以上是洛谷题解中的一种C++做法,那么对于这个问题,肯定要使用自己熟悉的语言来进行实现。
python如何解决这一个问题?
常规思路:遍历
1 | |
虽然确实符合思维逻辑,但是超时了。
那就使用算法,使用二分算法比较符合当前的情况,在python中,可以使用bisect库来实现。
二分实现:
1 | |
知识点补充(bisect库)
1 基础知识
前提:列表有序!!!
bisect()和bisect_right()等同,那下面就介绍bisect_left()和bisec_right()的区别!
用法:
1 | |
bisect.bisect和bisect.bisect_right返回大于x的第一个下标(相当于C++中的upper_bound),bisect.bisect_left返回大于等于x的第一个下标(相当于C++中的lower_bound)。
case1
如果列表中没有元素x,那么bisect_left(ls, x)和bisec_right(ls, x)返回相同的值,该值是x在ls中“合适的插入点索引,使得数组有序”。此时,ls[index2] > x,ls[index3] > x。
1 | |
程序运行结果为,
1 | |
case2
如果列表中只有一个元素等于x,那么bisect_left(ls, x)的值是x在ls中的索引,ls[index2] = x。而bisec_right(ls, x)的值是x在ls中的索引加1,ls[index3] > x。
1 | |
程序运行结果为,
1 | |
case3
如果列表中存在多个元素等于x,那么bisect_left(ls, x)返回最左边的那个索引,此时ls[index2] = x。bisect_right(ls, x)返回最右边的那个索引加1,此时ls[index3] > x。
1 | |
程序运行结果为,
1 | |
2 扩展知识
(一)
1 | |
rides:这是一个列表,已经按顺序排列。
start:这是我们要在rides中查找的元素。
hi = i - 1:这是查找的上界。具体而言,在[0, hi)这个左闭右开区间中,寻找满足rides[x][1] > start且x最小的case,返回x。如果没有找到,则返回hi。
key = lambda x : x[1]:这是用于比较的元素。默认情况下,bisect_right比较元素x的值,而这里表示比较元素x的下标等于1的元素的值(说明元素x是一个列表或元组等等),即x[1]。
参考文章:http://t.csdnimg.cn/ZdACV
P8681 [蓝桥杯 2019 省 AB] 完全二叉树的权值
题目描述
给定一棵包含 $N$ 个节点的完全二叉树,树上每个节点都有一个权值,按从上到下、从左到右的顺序依次是 $A_1,A_2, \cdots A_N$,如下图所示:
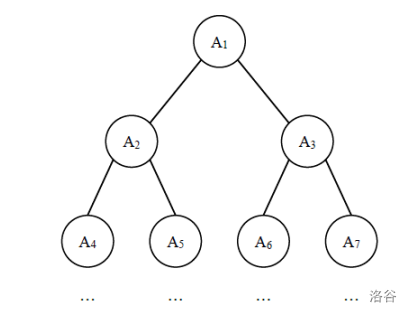
现在小明要把相同深度的节点的权值加在一起,他想知道哪个深度的节点权值之和最大?如果有多个深度的权值和同为最大,请你输出其中最小的深度。
注:根的深度是 $1$。
输入格式
第一行包含一个整数 $N$。
第二行包含 $N$ 个整数 $A_1,A_2, \cdots, A_N$。
输出格式
输出一个整数代表答案。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
对于所有评测用例,$1 \le N \le 10^5$,$0 \le |A_i| \le 10^5$。
蓝桥杯 2019 省赛 A 组 F 题(B 组 G 题)。
P4715 【深基16.例1】淘汰赛
题目描述
有 $2^n$($n\le7$)个国家参加世界杯决赛圈且进入淘汰赛环节。已经知道各个国家的能力值,且都不相等。能力值高的国家和能力值低的国家踢比赛时高者获胜。1 号国家和 2 号国家踢一场比赛,胜者晋级。3 号国家和 4 号国家也踢一场,胜者晋级……晋级后的国家用相同的方法继续完成赛程,直到决出冠军。给出各个国家的能力值,请问亚军是哪个国家?
输入格式
第一行一个整数 $n$,表示一共 $2^n$ 个国家参赛。
第二行 $2^n$ 个整数,第 $i$ 个整数表示编号为 $i$ 的国家的能力值($1\leq i \leq 2^n$)。
数据保证不存在平局。
输出格式
仅一个整数,表示亚军国家的编号。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
解题答案
1 | |
P4913 【深基16.例3】二叉树深度
题目描述
有一个 $n(n \le 10^6)$ 个结点的二叉树。给出每个结点的两个子结点编号(均不超过 $n$),建立一棵二叉树(根节点的编号为 $1$),如果是叶子结点,则输入 0 0。
建好这棵二叉树之后,请求出它的深度。二叉树的深度是指从根节点到叶子结点时,最多经过了几层。
输入格式
第一行一个整数 $n$,表示结点数。
之后 $n$ 行,第 $i$ 行两个整数 $l$、$r$,分别表示结点 $i$ 的左右子结点编号。若 $l=0$ 则表示无左子结点,$r=0$ 同理。
输出格式
一个整数,表示最大结点深度。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
解题答案
可以使用bfs或dfs进行求解
DFS搜索答案
1 | |
BFS搜索答案
1 | |
P1030 [NOIP2001 普及组] 求先序排列
题目描述
给出一棵二叉树的中序与后序排列。求出它的先序排列。(约定树结点用不同的大写字母表示,且二叉树的节点个数 $ \le 8$)。
输入格式
共两行,均为大写字母组成的字符串,表示一棵二叉树的中序与后序排列。
输出格式
共一行一个字符串,表示一棵二叉树的先序。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
【题目来源】
NOIP 2001 普及组第三题
解题思路
1 | |
1 | |
1 | |
P1157 组合的输出
题目描述
排列与组合是常用的数学方法,其中组合就是从 $n$ 个元素中抽出 $r$ 个元素(不分顺序且 $r \le n$),我们可以简单地将 $n$ 个元素理解为自然数 $1,2,\dots,n$,从中任取 $r$ 个数。
现要求你输出所有组合。
例如 $n=5,r=3$,所有组合为:
$123,124,125,134,135,145,234,235,245,345$。
输入格式
一行两个自然数 $n,r(1<n<21,0 \le r \le n)$。
输出格式
所有的组合,每一个组合占一行且其中的元素按由小到大的顺序排列,每个元素占三个字符的位置,所有的组合也按字典顺序。
注意哦!输出时,每个数字需要 $3$ 个场宽。以 C++ 为例,你可以使用下列代码:
1 | |
输出占 $3$ 个场宽的数 $x$。注意你需要头文件 iomanip。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
P3378 【模板】堆
题目描述
给定一个数列,初始为空,请支持下面三种操作:
- 给定一个整数 $x$,请将 $x$ 加入到数列中。
- 输出数列中最小的数。
- 删除数列中最小的数(如果有多个数最小,只删除 $1$ 个)。
输入格式
第一行是一个整数,表示操作的次数 $n$。
接下来 $n$ 行,每行表示一次操作。每行首先有一个整数 $op$ 表示操作类型。
- 若 $op = 1$,则后面有一个整数 $x$,表示要将 $x$ 加入数列。
- 若 $op = 2$,则表示要求输出数列中的最小数。
- 若 $op = 3$,则表示删除数列中的最小数。如果有多个数最小,只删除 $1$ 个。
输出格式
对于每个操作 $2$,输出一行一个整数表示答案。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
【数据规模与约定】
- 对于 $30%$ 的数据,保证 $n \leq 15$。
- 对于 $70%$ 的数据,保证 $n \leq 10^4$。
- 对于 $100%$ 的数据,保证 $1 \leq n \leq 10^6$,$1 \leq x \lt 2^{31}$,$op \in {1, 2, 3}$。
P1135 奇怪的电梯
题目背景
感谢 @yummy 提供的一些数据。
题目描述
呵呵,有一天我做了一个梦,梦见了一种很奇怪的电梯。大楼的每一层楼都可以停电梯,而且第 $i$ 层楼($1 \le i \le N$)上有一个数字 $K_i$($0 \le K_i \le N$)。电梯只有四个按钮:开,关,上,下。上下的层数等于当前楼层上的那个数字。当然,如果不能满足要求,相应的按钮就会失灵。例如: $3, 3, 1, 2, 5$ 代表了 $K_i$($K_1=3$,$K_2=3$,……),从 $1$ 楼开始。在 $1$ 楼,按“上”可以到 $4$ 楼,按“下”是不起作用的,因为没有 $-2$ 楼。那么,从 $A$ 楼到 $B$ 楼至少要按几次按钮呢?
输入格式
共二行。
第一行为三个用空格隔开的正整数,表示 $N, A, B$($1 \le N \le 200$,$1 \le A, B \le N$)。
第二行为 $N$ 个用空格隔开的非负整数,表示 $K_i$。
输出格式
一行,即最少按键次数,若无法到达,则输出 -1。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
对于 $100 %$ 的数据,$1 \le N \le 200$,$1 \le A, B \le N$,$0 \le K_i \le N$。
本题共 $16$ 个测试点,前 $15$ 个每个测试点 $6$ 分,最后一个测试点 $10$ 分。
P1334 瑞瑞的木板
题目背景
瑞瑞想要亲自修复在他的一个小牧场周围的围栏。
题目描述
他测量栅栏并发现他需要 $n$ 根木板,每根的长度为整数 $l_i$。于是,他买了一根足够长的木板,长度为所需的 $n$ 根木板的长度的总和,他决定将这根木板切成所需的 $n$ 根木板(瑞瑞在切割木板时不会产生木屑,不需考虑切割时损耗的长度)。
瑞瑞切割木板时使用的是一种特殊的方式,这种方式在将一根长度为 $x$ 的木板切为两根时,需要消耗 $x$ 个单位的能量。瑞瑞拥有无尽的能量,但现在提倡节约能量,所以作为榜样,他决定尽可能节约能量。显然,总共需要切割 $(n-1)$ 次,问题是,每次应该怎么切呢?请编程计算最少需要消耗的能量总和。
输入格式
输入的第一行是整数,表示所需木板的数量 $n$。
第 $2$ 到第 $(n + 1)$ 行,每行一个整数,第 $(i + 1)$ 行的整数 $l_i$ 代表第 $i$ 根木板的长度 $l_i$。
输出格式
一个整数,表示最少需要消耗的能量总和。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
输入输出样例 1 解释
将长度为 $21$ 的木板,第一次切割为长度为 $8$ 和长度为 $13$ 的,消耗 $21$ 个单位的能量,第二次将长度为 $13$ 的木板切割为长度为 $5$ 和 $8$ 的,消耗 $13$ 个单位的能量,共消耗 $34$ 个单位的能量,是消耗能量最小的方案。
数据规模与约定
- 对于 $100%$ 的数据,保证 $1\le n \le 2 \times 10^4$,$1 \leq l_i \leq 5 \times 10^4$。
P1631 序列合并
题目描述
有两个长度为 $N$ 的单调不降序列 $A,B$,在 $A,B$ 中各取一个数相加可以得到 $N^2$ 个和,求这 $N^2$ 个和中最小的 $N$ 个。
输入格式
第一行一个正整数 $N$;
第二行 $N$ 个整数 $A_{1\dots N}$。
第三行 $N$ 个整数 $B_{1\dots N}$。
输出格式
一行 $N$ 个整数,从小到大表示这 $N$ 个最小的和。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
对于 $50%$ 的数据,$N \le 10^3$。
对于 $100%$ 的数据,$1 \le N \le 10^5$,$1 \le a_i,b_i \le 10^9$。
P5657 [CSP-S2019] 格雷码
题目描述
通常,人们习惯将所有 $n$ 位二进制串按照字典序排列,例如所有 2 位二进制串按字典序从小到大排列为:00,01,10,11。
格雷码(Gray Code)是一种特殊的 $n$ 位二进制串排列法,它要求相邻的两个二进制串间恰好有一位不同,特别地,第一个串与最后一个串也算作相邻。
所有 2 位二进制串按格雷码排列的一个例子为:00,01,11,10。
$n$ 位格雷码不止一种,下面给出其中一种格雷码的生成算法:
- 1 位格雷码由两个 1 位二进制串组成,顺序为:0,1。
- $n + 1$ 位格雷码的前 $2^n$ 个二进制串,可以由依此算法生成的 $n$ 位格雷码(总共 $2^n$ 个 $n$ 位二进制串)按顺序排列,再在每个串前加一个前缀 0 构成。
- $n + 1$ 位格雷码的后 $2^n$ 个二进制串,可以由依此算法生成的 $n$ 位格雷码(总共 $2^n$ 个 $n$ 位二进制串)按逆序排列,再在每个串前加一个前缀 1 构成。
综上,$n + 1$ 位格雷码,由 $n$ 位格雷码的 $2^n$ 个二进制串按顺序排列再加前缀 0,和按逆序排列再加前缀 1 构成,共 $2^{n+1}$ 个二进制串。另外,对于 $n$ 位格雷码中的 $2^n$ 个 二进制串,我们按上述算法得到的排列顺序将它们从 $0 \sim 2^n - 1$ 编号。
按该算法,2 位格雷码可以这样推出:
- 已知 1 位格雷码为 0,1。
- 前两个格雷码为 00,01。后两个格雷码为 11,10。合并得到 00,01,11,10,编号依次为 0 ~ 3。
同理,3 位格雷码可以这样推出:
- 已知 2 位格雷码为:00,01,11,10。
- 前四个格雷码为:000,001,011,010。后四个格雷码为:110,111,101,100。合并得到:000,001,011,010,110,111,101,100,编号依次为 0 ~ 7。
现在给出 $n$,$k$,请你求出按上述算法生成的 $n$ 位格雷码中的 $k$ 号二进制串。
输入格式
仅一行两个整数 $n$,$k$,意义见题目描述。
输出格式
仅一行一个 $n$ 位二进制串表示答案。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
样例 #2
样例输入 #2
1 | |
样例输出 #2
1 | |
样例 #3
样例输入 #3
1 | |
样例输出 #3
1 | |
提示
【样例 1 解释】
2 位格雷码为:00,01,11,10,编号从 0∼3,因此 3 号串是 10。
【样例 2 解释】
3 位格雷码为:000,001,011,010,110,111,101,100,编号从 0∼7,因此 5 号串是 111。
【数据范围】
对于 $50%$ 的数据:$n \leq 10$
对于 $80%$ 的数据:$k \leq 5 \times 10^6$
对于 $95%$ 的数据:$k \leq 2^{63} - 1$
对于 $100%$ 的数据:$1 \leq n \leq 64$, $0 \leq k \lt 2^n$
P3884 [JLOI2009] 二叉树问题
题目描述
如下图所示的一棵二叉树的深度、宽度及结点间距离分别为:
- 深度:$4$
- 宽度:$4$
- 结点 8 和 6 之间的距离:$8$
- 结点 7 和 6 之间的距离:$3$
其中宽度表示二叉树上同一层最多的结点个数,节点 $u, v$ 之间的距离表示从 $u$ 到 $v$ 的最短有向路径上向根节点的边数的两倍加上向叶节点的边数。
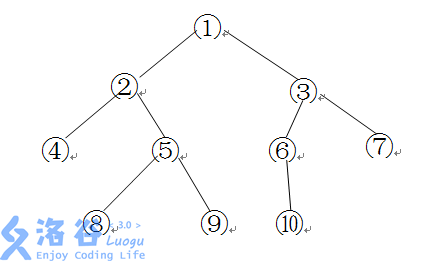
给定一颗以 1 号结点为根的二叉树,请求出其深度、宽度和两个指定节点 $x, y$ 之间的距离。
输入格式
第一行是一个整数,表示树的结点个数 $n$。
接下来 $n - 1$ 行,每行两个整数 $u, v$,表示树上存在一条连接 $u, v$ 的边。
最后一行有两个整数 $x, y$,表示求 $x, y$ 之间的距离。
输出格式
输出三行,每行一个整数,依次表示二叉树的深度、宽度和 $x, y$ 之间的距离。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
对于全部的测试点,保证 $1 \leq u, v, x, y \leq n \leq 100$,且给出的是一棵树。
解题思路
读题可知题目需要求出二叉树的深度宽度与两点间最短路径,这其实是三个问题分别解决并输出,求宽度与深度可以在一个dfs中完成,开数组记录每一深度下的节点数,最大的即为宽度,对于最短路径则使用bfs,用队列保存节点,每次弹出队头并加入左右父节点,左右节点则路径加一,父节点则路径加二,直到搜索到目的。
1 | |
P6915 [ICPC2015 WF] Weather Report
题面翻译
给定4种天气情况出现的概率,你需要将n天的所有可能的 $4^{n}$ 种情况已某种方式编码为01串,使得:
- 编码长度的期望最短
- 任何一个编码不是另一个编码的前缀
求期望长度。
题目描述

You have been hired by the Association for Climatological Measurement, a scientific organization interested in tracking global weather trends over a long period of time. Of course, this is no easy task. They have deployed many small devices around the world, designed to take periodic measurements of the local weather conditions. These are cheap devices with somewhat restricted capabilities. Every day they observe which of the four standard kinds of weather occurred: Sunny, Cloudy, Rainy, or Frogs. After every $n$ of these observations have been made, the results are reported to the main server for analysis. However, the massive number of devices has caused the available communication bandwidth to be overloaded. The Association needs your help to come up with a method of compressing these reports into fewer bits.
For a particular device’s location, you may assume that the weather each day is an independent random event, and you are given the predicted probabilities of the four possible weather types. Each of the $4^ n$ possible weather reports for a device must be encoded as a unique sequence of bits, such that no sequence is a prefix of any other sequence (an important property, or else the server would not know when each sequence ends). The goal is to use an encoding that minimizes the expected number of transmitted bits.
输入格式
The first line of input contains an integer $1 \le n \le 20$, the number of observations that go into each report. The second line contains four positive floating-point numbers, $p_{\text {sunny}}$, $p_{\text {cloudy}}$, $p_{\text {rainy}}$, and $p_{\text {frogs}}$, representing the respective weather probabilities. These probabilities have at most 6 digits after the decimal point and sum to 1.
输出格式
Display the minimum expected number of bits in the encoding of a report, with an absolute or relative error of at most $10^{-4}$.
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
样例 #2
样例输入 #2
1 | |
样例输出 #2
1 | |
提示
Time limit: 1000 ms, Memory limit: 1048576 kB.
International Collegiate Programming Contest (ACM-ICPC) World Finals 2015
解题思路
- 给出四种天气出现的概率(每天都一样),要求把nnn天中4n4n4^n种可能的天气序列映射成010101串,满足任何一个010101串不是另一个010101串的前缀,且期望串长最短。
- n≤20n≤20n\le20
哈夫曼树:堆+贪心
哈夫曼树是满足∑x∈leafdepx×valx∑x∈leafdepx×valx\sum_{x\in leaf}dep_x\times val_x最小的二叉树。
把4n4n4^n种可能的天气序列看作叶节点,valxvalxval_x取每种天气数列出现的概率,发现上面的式子恰好就是期望的计算式。因此,只要建出哈夫曼树就解决了这道题目。
4n4n4^n太大不可能直接单独考虑每种天气序列。发现一种天气序列的概率只取决于其中每种天气各自的个数而与顺序无关,因此不同的概率只有C3n+3Cn+33C_{n+3}^3种,我们可以把相同的概率绑成一个pairpairpair一起求解。
求解的过程就是经典的堆+贪心,每次取出最小元素,先让它自己尽可能两两配对,如果有一个多余的就再和新的堆顶配对。
答案
1 | |
P3916 图的遍历
题目描述
给出 $N$ 个点,$M$ 条边的有向图,对于每个点 $v$,求 $A(v)$ 表示从点 $v$ 出发,能到达的编号最大的点。
输入格式
第 $1$ 行 $2$ 个整数 $N,M$,表示点数和边数。
接下来 $M$ 行,每行 $2$ 个整数 $U_i,V_i$,表示边 $(U_i,V_i)$。点用 $1,2,\dots,N$ 编号。
输出格式
一行 $N$ 个整数 $A(1),A(2),\dots,A(N)$。
样例 #1
样例输入 #1
1 | |
样例输出 #1
1 | |
提示
- 对于 $60%$ 的数据,$1 \leq N,M \leq 10^3$。
- 对于 $100%$ 的数据,$1 \leq N,M \leq 10^5$。
解题思路
使用链式前向星
1 | |