python网络爬虫
First Post:
Last Update:
Last Update:
第1章 爬虫介绍
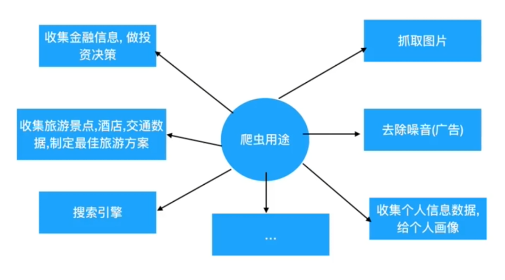
爬虫用途
爬虫分类
按照使用场景:
通用爬虫
全网爬虫
从一些种子url扩展到整个WEB爬虫,是搜索引擎的重要组成部分
特点:
- 爬取范围广
- 对硬件要求高(CPU,存储空间)
- 更新频率低
聚焦爬虫
主题爬虫
只爬取相关主题页面
特点:
- 爬虫范围窄
- 对硬件要求低
- 更新频率快
按爬取方式:
累积式爬虫
从某个时间开始,遍历所有的能够爬取的URL,爬取相关数据,只要硬件和时间允许就可以累计大量数据
特点
- 爬取页面比较多
- 对硬件要求高
- 数据更新慢
增量式爬虫
在有客观数据基础上,只能爬取没有的数据或者更新的数据,而对于没有变化的数据就不在爬取了
特点
- 爬取页面比较少
- 对硬件要求不高
- 数据更新比较快
按爬取页面存在的方式:
表层网络爬虫
表层页面
- 通过url就能直接获取的HTML页面
爬取表层页面的爬虫
深层网络爬虫
深层网页
- 通过AJAX请求才能获取数据,动态生成的数据
- 登录之后才能访问的数据